




Inhalt
Während signatur- bzw. regelbasierte Erkennungsmethoden sehr zuverlässig im Kontext bekannter Gefahren eingesetzt werden können, sind gewisse Angriffsszenarien durch diese Methoden nicht adressierbar. Die zunehmende Komplexität, Kreativität sowie Entwicklungsgeschwindigkeit neuer Angriffsmethoden oder Varianten bereits bekannter stellt signaturgestützte Detektionsverfahren vor Herausforderungen. Es bedarf zusätzlicher Ansätze, welche in der Lage sind, ein solches System dort zu unterstützen, wo Signaturen und Regeln nicht mehr effektiv eingesetzt werden können.
Damit betreten wir den Bereich der Anomalieerkennung. Diese Verfahren erlernen zunächst das normale Verhalten der Umgebung, in welcher sie sich befinden, und beobachten diese. Ist nun eine signifikante Abweichung des üblichen Verhaltens festzustellen, führt dies zu einem Alarm. Geeignet ist ein solcher Ansatz zu Zwecken der Angriffserkennung, da Angriffe als eine Abweichung des Normalbetriebes eines Systems interpretiert werden können. Somit ist die Anomalieerkennung zu Zwecken der Angriffsdetektion ein in der Theorie gangbarer Weg.
Dieser Entwurf erlaubt implizit Angriffsmethoden zu entdecken, welche
- mittels Signaturen nicht adressiert werden können
- neuartiger Natur sind.
Letzteres liegt daran, dass der Ansatz nicht nach konkreten Angriffen sucht. Vielmehr erkennt es die Konsequenz dieser, nämlich das veränderte Verhalten der Umgebung, welches durch den Angriff verursacht wird. Unser SECUINFRA Cyber Defense Expertenteam forscht kontinuierlich an der Anomalieerkennung mithilfe von Deep Learning, um Angriffe auf Netzwerkebene zu identifizieren.
Mit diesem Artikel möchten wir, möglichst einsteigerfreundlich, einen nicht-technischen Überblick über die Methodik und Idee bieten.
Eine Einordnung
Bevor wir das Thema der Anomalieerkennung detaillierter ausführen, möchten wir zunächst eine kurze Einordnung schaffen. Diese soll helfen zu verstehen, welche Bereiche das Thema künstliche Intelligenz unter anderem umfasst und wo sich dabei unsere Forschungsarbeit einreiht.
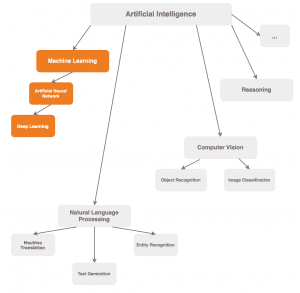
In der Literatur trifft man hierzu auf eine Vielzahl verschiedener Interpretationen, wie die einzelnen Bereiche in der künstlichen Intelligenz einzuordnen sind, beziehungsweise aus welchen diese besteht. Daher dient diese nicht vollständige Grafik dem Zweck einer losen Orientierung.
Machine Learning ist derzeit das Feld, dem der Großteil der öffentlichen Aufmerksamkeit zuteil wird. Diese Verfahren sind in der Lage, Gesetzmäßigkeiten in historischen Daten zu erfassen. Dabei unterscheidet sich der Vorgang interessanterweise gar nicht so sehr von der Art und Weise, wie wir Menschen lernen: Aus Beobachtungen und Erfahrungen generalisieren wir und schaffen auf diese Weise Wissen. Analog ist ein solches Verfahren ebenso in der Lage, durch die erkannten Muster und Charakteristiken zukünftig für unbekannte Daten Lösungen selbstständig zu ermitteln.
Deep Learning bezieht sich hierbei auf eine Familie von Verfahren in der Machine Learning Domäne. Hier sprechen wir von künstlichen neuronalen Netzen. Von Deep Learning spricht man, wenn die Architektur des neuronalen Netzes eine gewisse Komplexität aufweist. Dies werden wir noch eingehender in dem Abschnitt erläutern, der den Aufbau solcher Netze thematisiert.
Beginnen wir nun aber mit dem wohl wichtigsten Abschnitt unserer Arbeit.
Die Daten
Die Qualität der Ergebnisse ist direkt von der Qualität der Daten abhängig. Auf den ersten Blick einleuchtend, stellt dies aber eine der größten Herausforderungen dar:
- Welche Daten erfasse ich?
- „Sprechen“ die Daten das, wonach ich suche?
- Das heißt, ist an dem, was ich beobachte, überhaupt ein Eindringen in meine Netzwerkinfrastruktur sichtbar?
- In welcher Form erwartet meine Methode die Daten, damit sie daraus wirklich lernen kann?
Das sind nur einige Fragen, die es zu beantworten gilt, wenn es um die Datengrundlage geht. Dieser Abschnitt stellt den zeitintensivsten Aspekt dar. Die Herausforderung besteht darin, die Daten so zu wählen und aufzubereiten, dass unser Verfahren in der Lage ist zu sehen, was wir von ihm möchten, das es sieht.
Die Basis bilden Netzwerkdaten, besser gesagt: Mitschnitte in Form von PCAPs, welche die Kommunikation erfassen. Pro Beobachtung werden hier diverse Eigenschaften extrahiert. Diese Eigenschaften werden wir ab hier als Feature bezeichnen. Das ist in der Machine Learning Domäne der geläufige Begriff für „Eigenschaften von Beobachtungen“.
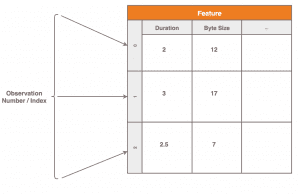
Wie in der Abbildung zu sehen, werden in unserem Beispiel pro Beobachtung die Features „Übertragungsdauer“ und „Größe der übertragenen Daten“ erfasst.
Hier erkennt man, dass:
- eine Zeile einer Beobachtung entspricht
- eine Spalte den Werteverlauf eines Features über die Zeit repräsentiert
- also über alle Beobachtungen
Mit zunehmender Anzahl Beobachtungen zeichnet sich ein gewisses Grundverhalten in jedem unserer Feature ab.
- Welche Werte treten in diesem Feature im Verlauf der Zeit besonders häufig auf?
- Um wieviel streuen die Werte allgemein um diesen häufigsten Wert?
- In welchem Wertebereich bewegen sich die Werte üblicherweise?
Je mehr dieser Beobachtungen verfügbar werden, umso zuverlässiger lassen sich diese Fragen beantworten.
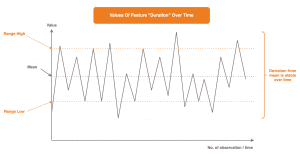
Diese Grafik zeigt ein sehr deutliches Bild über die Werteentwicklung im Feature der Übertragungsdauer: Die Werte bewegen sich überwiegend in einem wohldefinierten Wertebereich, hier mit „Range Low“ und „Range High“ gekennzeichnet. Ausreißer sind nicht sichtbar, beziehungsweise die Schwankung vom Durchschnitt ist konstant. Ein klares Verhaltensbild. Hier ist anzumerken, dass in der Praxis üblicherweise diverse Vorverarbeitungs- und Bereinigungsschritte notwendig sind, bevor man ein solch klares Bild über die Daten erhält. Die Grafik zeigt sozusagen bereits den Idealfall.
Nun gilt es, dieses Verhalten mit all seinen Eigenschaften und Mustern zu erfassen: Hierzu machen wir uns Deep Learning zu Nutze.
Künstliche Neuronale Netze
Die Architektur
Künstliche neuronale Netze sind lose durch das menschliche Gehirn inspiriert. Sie bestehen aus Neuronen, welche durch eine Vielzahl von Verbindungen mittels Signalen in Form numerischer Werte kommunizieren. Bei einem Neuron handelt es sich um eine Komponente, welche mathematische Operationen auf seinen Eingaben durchführt. Das Ergebnis entscheidet, mit welcher Intensität oder ob überhaupt ein Signal an die Neuronen der nachfolgenden Schicht gesendet werden soll.
Die Eingaben an ein Neuron bestehen aus:
- Ausgaben der Neuronen der vorherigen Schicht
- Koeffizienten, auch Weights genannt
Diese beiden Komponenten werden kombiniert und durch das Neuron verarbeitet. Neuronen sind dabei in Schichten angeordnet. Diese Schichten werden jeweils als Eingabe-, Ausgabe- oder verborgene Schicht bezeichnet, je nach Lage im Netz.
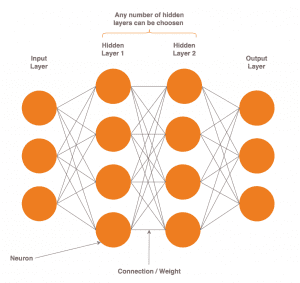
Ab einer gewissen Anzahl verborgener Schichten spricht man von „Deep Learning“, üblicherweise drei aufwärts. Das bedeutet, Deep Learning ist eine Unterkategorie künstlicher neuronaler Netze, wie zu Beginn des Artikels in der Abbildung bereits gezeigt worden ist. Das Ziel neuronaler Netze ist es, Muster in Daten zu erfassen, welche wir ihnen präsentieren. Dabei ist irrelevant, um welche Daten es sich handelt. Bilder, Videos, Sensordaten, akustische Information, nur um ein paar Beispiele zu nennen. Solange es sich numerisch darstellen lässt, ist es grundsätzlich zur Verarbeitung geeignet.
Der Lernvorgang
Der Lernvorgang, beziehungsweise das Training, ist der Prozess der Extraktion signifikanter Muster und Gesetzmäßigkeiten aus historischen Daten, welche selbige grundlegend definieren.
Vor Beginn wählen wir die Daten, welche in das neuronale Netzwerk eingegeben werden (unsere Beobachtungen) und die von uns erwarteten Ausgaben pro Eingabe. Der Lernalgorithmus beginnt damit, dass das neuronale Netzwerk pro Eingabe die korrespondierende Ausgabe gewissermaßen rät. Da wir die erwartete Ausgabe kennen, kann hieraus ein Fehlerwert berechnet werden. Der Fehler ist, mit anderen Worten, eine Metrik die aussagt: „Wie falsch lag mein neuronales Netz mit seinem Ergebnis gegenüber dem erwarteten Wert für diese Beobachtung?“
Dieser Fehlerwert wird nun herangezogen, um die Weights des neuronalen Netzes so anzupassen, dass der Fehler beim nächsten Versuch geringer ausfällt. Das passiert im Kontext jeder präsentierten Beobachtung. Man kann sich jede Schicht, beziehungsweise deren Ausgaben, als eine Abstraktion unserer Eingabe vorstellen. Jede Schicht, außer die erste, arbeitet also auf einer Darstellung unserer ursprünglichen Eingabe, welche sie von der vorherigen Schicht erhalten hat. Je weiter unsere Eingabe im neuronalen Netzwerk voranschreitet, umso mehr wird sie reorganisiert und aggregiert. Die Weights dienen dazu, bei den Abstraktionen jeder Schicht die Elemente hervorzuheben, welche am relevantesten sind, um Ausgaben zu generieren, die möglichst nahe an unseren erwarteten Zielwerten liegen. Somit erlangt im Zuge des Lernvorgangs das neuronale Netz zunehmend die Fähigkeit, sich auf die Muster und Charakteristiken zu fokussieren, welche die tatsächlich unterliegende Beziehung zwischen allen Eingabe-Zielwert Pärchen beschreiben.
Nachdem alle Eingabedaten einmal präsentiert worden sind, Ausgaben dazu generiert wurden und die Fehlerwerte zur Parameter-Optimierung genutzt worden sind, wird der Vorgang wiederholt. Und zwar mehrere, möglicherweise hunderte Male. Im Idealfall jedoch jedes Mal mit einer leicht verbesserten Version des neuronalen Netzwerkes als im vorherigen Durchlauf, was sich in einem immer geringer werdendem Fehlerwert äußert.
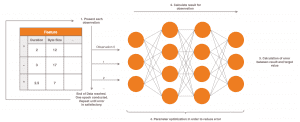
Das Ergebnis dieses Vorgangs ist ein sogenanntes Modell. Die Namensgebung ergibt sich aus dem Umstand, dass das Training dazu dient die zugrundeliegenden Zusammenhänge zwischen den Eingaben und Zielwerten zu modellieren. Im besten Fall ist dieses Modell nun durch das Gelernte in der Lage adäquat zu generalisieren, um zukünftig neue Eingaben in Ausgaben zu überführen, deren Zielwerte unbekannt sind. Die Aufgabe des Modells ist es nun, diese zukünftig selbst zu ermitteln.
Ob das Modell dies zufriedenstellend erfüllt, kann nach dem Training evaluiert werden. Hierzu nutzen wir einen weiteren Datensatz aus Eingabewerten und dazu bekannten Zielwerten. Hier lassen wir für diese (in dem Training zuvor nicht präsentierten) Beobachtungen durch das Modell erneut Ausgaben erzeugen. Diese werden dann wieder mit den tatsächlichen Zielwerten verglichen. Dieser Vorgang simuliert den Produktiveinsatz. Ist der Fehler im Zusammenhang mit diesem unabhängigen Datensatz vergleichbar mit jenem zur Schlussphase des Trainings? Wenn ja, bedeutet dies, dass das neuronale Netzwerk höchstwahrscheinlich im Zuge des Lernprozesses die Muster und Aspekte in den Eingabedaten erfassen konnte, mit welchen von den Eingaben auf die Zielwerte geschlossen werden kann.
Exkurs: Ein Spielbeispiel
An dieser Stelle sei betont, das die vordefinierten Zielwerte beliebig sein können. Es gibt keine semantischen Einschränkungen, auf was man von seinen Eingaben abbilden kann. Sinnvoll sind aber nur Paarungen aus Eingaben und Zielwerten, bei denen der Zielwert auch wirklich aus der Eingabe abgeleitet werden kann und wo diese Beziehung erlernbar beziehungsweise überhaupt existent ist.
Ob das zutrifft, ist im übrigen vorher nicht immer bekannt und auch nicht unbedingt feststellbar.
Ein Beispiel hierfür wäre der Versuch der Vorhersage zukünftiger Preisentwicklungen einer Aktie anhand vergangener Trends und Preisbewegungen.
Sofern die Random Walk Theorie gilt, implizieren historische Preisbewegungen nicht jene in der Zukunft. Somit ist eine Vorhersage zukünftiger Preise basierend auf vergangenen Bewegungen per Definition nicht möglich. Daher wird man dieses Problem auch nicht mit neuronalen Netzen lösen können.
Nun ist die Angelegenheit aber nicht ganz so eindeutig. Die Gegenannahme ist, dass bestimmte immer wieder auftretende Muster, welche durch Preisverläufe gebildet werden, die Wahrscheinlichkeit für einen anschließend steigenden oder fallenden Kurs erhöhen. Das Erkennen und entsprechende Handeln danach bildet eine Grundsäule der Arbeit eines jeden Traders.
Nach dieser These könnte man also anhand vergangener Preisbewegungen durchaus auf die Zukunft schließen und Empfehlungen im Stile von „Buy“ oder „Sell“ mithilfe neuronaler Netze generieren lassen, je nach beobachtetem Preisbewegungsmuster.
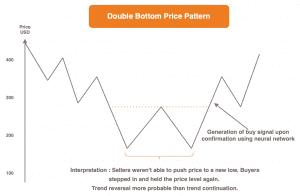
Welche der beiden Theorien nun tatsächlich zutrifft, da scheiden sich die Geister.
Dieses Beispiel dient aber hier nur der Veranschaulichung. Denn je nach Problemstellung kann vorher nicht mit Sicherheit festgestellt werden, ob die Zielwerte aus den Eingaben hergeleitet werden können. Die beste Option, die sich einem in einem solchen Fall bietet, ist tatsächlich es „einfach auszuprobieren“.
Ansatz zur Erkennung von Angriffen im Netzwerk mittels Deep Learning
Nun wollen wir zu guter Letzt darauf eingehen, wie wir uns das zu Zwecken der Angriffserkennung zu Nutze machen möchten.
Das übergeordnete Ziel ist, das normale Verhalten der Computernetzwerkumgebung zu erfassen. Das bedeutet, dass unsere Netzwerkkommunikationsdaten so aufbereitet und unser neuronales Netzwerk so konstruiert werden muss, dass es lernen kann, welche Grundcharakteristiken unsere Daten definieren. Es gibt hier verschiedene Möglichkeiten, wie das technisch im Lernvorgang umgesetzt werden kann.
Gegeben, dass eine Beobachtung im Netzwerk als Eingabe herangezogen wird, sind zwei mögliche Optionen:
- den Zielwert auf zeitlich nach der Eingabe folgende Beobachtungen zu setzen
- den Zielwert gleich der Eingabe zu setzen.
Variante 1. ist gangbar, da das Vorhersagen zukünftigen Netzwerkverhaltens mit hinreichend geringem Fehler als erfolgreiche Modellierung der Computernetzwerkkommunikation gedeutet werden kann. Das neuronale Netzwerk muss lernen, „einen Blick in die Zukunft zu werfen“ – und das ist nur mit einem grundlegenden Verständnis über das Verhalten im Computernetzwerk möglich.
Variante 2. ist ebenso valide, da hier aus den verschiedenen Abstraktionen der Eingaben über alle Schichten hinweg gelernt werden muss, aus diesen die Eingaben selbst wiederherzustellen.
Meist werden neuronale Netzwerke in Variante 2. so konstruiert, dass über die verborgenen Schichten Kompression und somit Datenverlust erzwungen wird. Das dient der Forcierung, nur die relevanten Informationen aus den Eingaben zu extrahieren, um so zu lernen, aus diesen alleine wieder auf die Eingaben zu schließen.
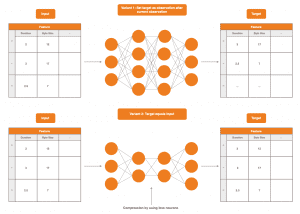
Die Idee zur Nutzung dieses Entwurfes zur Angriffserkennung ist nun wie folgt:
Ein durch einen Angriff verursachtes Verhalten stellt eine Abweichung vom normalen Verhalten des Computernetzwerkes dar.
Das Verhalten des Computernetzwerkes im Angriffsfall wird nämlich andere Charakteristiken und Eigenschaften aufweisen, als das beobachtete Verhalten im Falle harmloser, täglicher Netzwerkkommunikation.
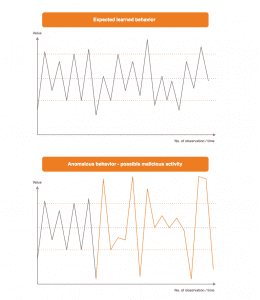
In diesem Moment ist ein erhöhter Fehler zwischen den Ausgaben des neuronalen Netzwerkes und den tatsächlichen Netzwerkbeobachtungen zu erwarten. Das neuronale Netzwerk „rechnet“ nicht mit dieser Veränderung, weil es im Zuge des Lernvorgangs Verhaltensmuster in der Netzwerkkommunikation, welche durch Angriffe hervorgerufen werden, nicht gesehen und gelernt hat. Der erhöhte Fehler stellt damit einen Indikator für einen möglichen Angriff dar.
Ein solcher Entwurf erlaubt in der Theorie die Detektion aller Angriffe, vorausgesetzt sie verursachen in den beobachteten Features merkliche Verhaltensveränderungen. Ein sehr vielversprechender Ansatz, aber unter anderem wegen des Aspekts der Universalität ein ebenso herausfordernder. Daher ist dies nach wie vor ein weites Forschungsthema.
Wir hoffen, Sie konnten in diesem Artikel einen Einblick in die Thematik der Anomalie- beziehungsweise Angriffserkennung mittels Deep Learning erlangen. Die SECUINFRA wird weiter daran forschen, wie Methoden der künstlichen Intelligenz für die Zwecke der Cybersecurity genutzt werden können. Damit wir den Gefahren von morgen schon heute begegnen können.
