




Content
While signature- or rule-based detection methods can be used very reliably in the context of known threats, certain attack scenarios cannot be addressed by these methods.
The increasing complexity, creativity, and speed of development of new attack methods or variants of already known ones pose challenges for signature-based detection methods.
Additional approaches are needed that are able to support such a system where signatures and rules can no longer be used effectively.
Thus, we enter the field of anomaly detection.
These methods first learn the normal behavior of the environment in which they are located and observe it.
If there is now a significant deviation from the normal behavior, this leads to an alarm.
Such an approach is suitable for attack detection purposes, since attacks can be interpreted as a deviation from the normal operation of a system.
Thus, anomaly detection for attack detection purposes is a viable approach in theory.
This design implicitly allows to detect attack methods that:
- cannot be addressed by signatures
- are novel
The latter is because the approach does not look for specific attacks.
Rather, it detects the consequence of these, namely the changed behavior of the environment caused by the attack.
At SECUINFRA, we are researching anomaly detection using Deep Learning to identify network-level attacks.
In this article, we would like to provide, in the most beginner-friendly way possible, a non-technical overview of the methodology and idea.
An overview
However, before we elaborate on this topic more extensively, let’s first create a brief overview.
This should help to understand which areas the topic of artificial intelligence covers and where our research work fits in.
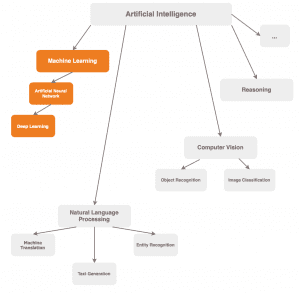
In the literature, there are many different interpretations of how the individual areas of artificial intelligence are to be classified or what they consist of.
Therefore, this non-exhaustive chart serves the purpose of a loose orientation.
Machine learning is probably the field that receives most of the public attention.
These methods are able to detect regularities in historical data.
This process is not so different from the way we humans learn.
We generalize from observations and experiences and create knowledge in this way.
Analogously, such a process is also capable of independently determining solutions for unknown data in the future through the recognized patterns and characteristics.
Deep Learning refers to a family of methods in the Machine Learning domain.
Here we speak of artificial neural networks. We speak of Deep Learning when the architecture of the neural network has a certain complexity.
We will explain this in more detail in the section that discusses the structure of such networks.
But now let’s start with the probably most important section of our work.
The data
The quality of the results is directly dependent on the quality of the data. While obvious at first glance, this is one of the biggest challenges.
What data am I collecting?
Does the data “speak” what I am looking for?
That is, is there any intrusion into my network infrastructure visible at all in what I am observing?
What form does my method expect the data to take so that it can truly learn from it?
These are just a few of the questions that need to be answered when it comes to the data foundation.
This section represents the most time-consuming aspect.
The task is to select and prepare the data in such a way that our method is able to see what we want it to see.
The basis is network data, or rather recordings in the form of PCAPs, which capture the communication.
Per observation, various features are extracted here.
From here on, we will refer to these properties as features.
In the machine learning domain, this is the common term for “properties of observations”.
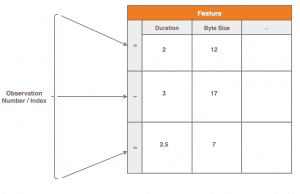
As can be seen in the figure, in our example the features “transmission duration” and “size of the transmitted data” are recorded per observation.
What can be seen here is that:
- one row corresponds to one observation
- a column represents the value progression of a feature over time
- i.e. over all observations
As the number of observations increases, a certain basic behavior emerges in each of our features.
Which values occur particularly frequently in this feature over time?
By how much do the values generally scatter around this most frequent value?
In what range of values do the values usually range?
The more of these observations become available, the more reliably these questions can be answered.
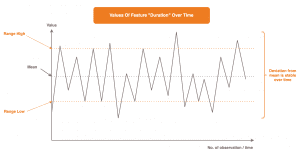
This graphic shows a very nice and clear picture of the value development in the transmission duration feature.
The values are predominantly within a well-defined value range, marked here with “Range Low” and “Range High”. Outliers are not visible and the variation from the average is constant. A clear behavioral picture.
It should be noted here that in practice, various pre-processing and cleaning steps are usually necessary before such a clear picture of the data is obtained. The graphic already shows the ideal case, so to speak.
Now we need to capture this behavior with all its properties and patterns.
For this purpose, we make use of Deep Learning.
Artificial Neural Networks
The architecture
Artificial neural networks are loosely inspired by the human brain.
They consist of neurons that communicate through a multitude of connections using signals in the form of numerical values.
A neuron is a component that performs mathematical operations on its inputs.
The result decides with which intensity or if at all a signal should be sent to the neurons of the following layer.
The inputs to a neuron consist of:
- Outputs from the neurons of the previous layer
- Coefficients, also called weights
These two components are combined and processed by the neuron.
Neurons are arranged in layers.
These layers are respectively called input, output, or hidden layer, depending on their location in the network.
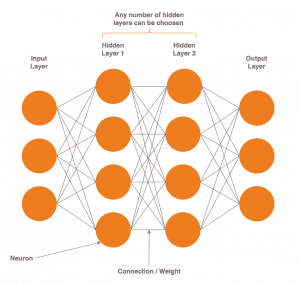
From a certain number of hidden layers one speaks of “Deep Learning”, usually three upwards.
This means Deep Learning is a subcategory of artificial neural networks, as already shown in the figure at the beginning of the article.
The goal of neural networks is to capture patterns in data that we present to them.
It is irrelevant what the data is. Images, videos, sensor data, acoustic information, just to name a few examples. As long as it can be represented numerically, it is basically suitable for processing.
The learning process
Learning is the process of extracting significant patterns and regularities from historical data that fundamentally define it.
Before starting, we choose the data that will be input to the neural network (our observations) and the outputs we expect per input.
The learning algorithm starts with the neural network guessing the corresponding output per input.
Since we know the expected output, an error value can be calculated from this.
The error is, in other words, a metric that says: “How wrong was my neural network with its output compared to the expected value for this observation?”
This error value is now used to adjust the neural network’s weights so that the error is smaller on the next trial.
This happens in the context of each observation presented.
You can think of each layer, or its outputs, as an abstraction of our input.
So each layer, except the first, operates on a representation of our original input, which it received from the previous layer.
As our input progresses through the neural network, it becomes more reorganized and aggregated.
The weights are used to highlight the elements in the abstractions of each layer that are most relevant to generate outputs that are as close as possible to our expected target values.
Thus, as learning proceeds, the neural network increasingly acquires the ability to focus on the patterns and characteristics that describe the actual underlying relationship between all input-target value pairs.
After all input data has been presented once, outputs have been generated to it, and the error values have been used for parameter optimization, the process is repeated. Several times, possibly hundreds of times.
Ideally, however, each time with a slightly improved version of the neural network than in the previous run, resulting in an ever decreasing error value.
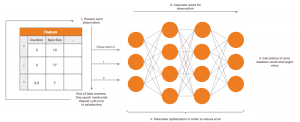
The result of this process is a so-called model. The name is derived from the fact that the training serves to model the underlying relationships between the inputs and target values.
In the best case, this model is now able to generalize adequately through what it has learned in order to convert new inputs into outputs in the future whose target values are unknown. The task of the model is now to determine these values itself in the future.
Whether the model does this satisfactorily can be evaluated after training. For this purpose, we use another data set consisting of input values and known target values. Here we let the model generate new outputs for these observations (which were not presented in the training before). These are then compared again with the actual target values. This process simulates productive use.
Is the error associated with this independent data set comparable to that at the final stage of training? If yes, this means that the neural network was most likely able to capture the patterns and aspects in the input data during the learning process, which can be used to infer the target values from the inputs.
Excursus
At this point it should be emphasized that the predefined target values can be arbitrary.
There are no semantic restrictions on what you can map from your inputs.
However, only pairings of inputs and target values are useful, where the target value can really be derived from the input and where this relation can be learned or exists at all.
Whether this is true, by the way, is not always known beforehand and also not necessarily ascertainable.
An example would be the attempt to predict future price developments of a stock based on past trends and price movements.
If the random walk theory holds, historical price movements do not imply those in the future.
Thus, predicting future prices based on past movements is by definition impossible.
Therefore, one will not be able to solve this problem with neural networks.
Now the matter is not quite so clear-cut.
The counter assumption is that certain recurring patterns, which are formed by price movements, increase the probability of a subsequent rising or falling price.
Recognizing and acting accordingly forms a basic pillar of every trader’s work.
According to this thesis, it is possible to draw conclusions about the future based on past price movements and to generate recommendations in the style of “buy” or “sell” with the help of neural networks, depending on the observed price movement pattern.
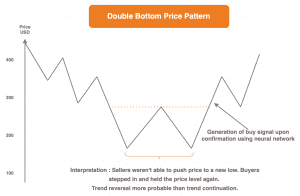
Opinions differ as to which of the two theories is actually correct.
However, this example only serves as an illustration.
Depending on the problem, it cannot be determined with certainty beforehand whether the target values can be derived from the inputs.
The best option in such a case is indeed to “just try it out”.
Approach to network attack detection using Deep Learning
Now, last but not least, let’s talk about how we want to take advantage of this for attack detection purposes.
The overall goal is to capture the normal behavior of the computer network environment. This means that our network communication data must be processed and our neural network must be constructed in such a way that it can learn what basic characteristics define our data.
There are several ways in which this can be technically implemented in the learning process.
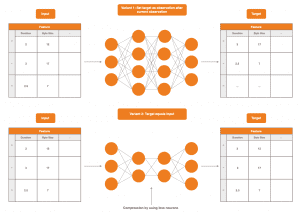
Given that an observation in the network is taken as input, two possible approaches are:
- to set the target value to observations after the input in time
- to set the target value equal to the input
Option 1. is viable, since predicting future network behavior with sufficiently small error can be interpreted as successfully modeling computer network communication.
The neural network must learn to “look into the future” and this is only possible with a basic understanding of computer network behavior.
Variant 2. is equally valid, since here it must learn to recover from the various abstractions of the inputs across all layers the inputs themselves.
Usually neural networks in variant 2. are constructed in such a way that over the hidden layers compression and thus data loss is forced.
This serves the forcing to extract only the relevant information from the inputs in order to learn from these alone to infer the inputs again.
The idea of using this design for attack detection is now as follows:
Behavior caused by an attack represents a deviation from the normal behavior of the computer network.
Namely, the behavior of the computer network in the case of an attack will have different characteristics and properties than the observed behavior in the case of harmless, daily network communication.
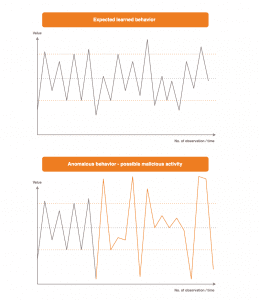
At this moment, an increased error between the neural network outputs and the actual network observations is to be expected.
The neural network does not “expect” this change, because in the course of the learning process it has not seen and learned behavior patterns in the network communication, which are caused by attacks.
The increased error thus represents an indicator of a possible attack.
Such a design allows in theory the detection of all attacks, provided they cause noticeable behavioral changes in the observed features.
A very nice approach but just as challenging because of the discussed aspect of universality in regard to attack detection, for example. Therefore, this is still an open research topic.
We hope that this article has given you an insight into the topic of anomaly and attack detection using Deep Learning.
SECUINFRA will continue to research how artificial intelligence methods can be used for cybersecurity purposes.
So that we can counter tomorrow’s threats today.
